
May 26, 2022
Building a Bulk Asynchronous Bird Recipient Validation Tool
One of the questions we occasionally receive is, how can I bulk validate email lists with validation du destinataire? There are two options here, one is to upload a file through the SparkPost UI for validation, and the other is to make individual calls per email à la API (as the API is single email validation).
La première option fonctionne très bien, mais elle est limitée à 20 Mo (environ 500 000 adresses). Que se passe-t-il si quelqu'un possède une liste d'adresses électroniques contenant des millions d'adresses ? Il faudrait alors diviser cette liste en plusieurs milliers de téléchargements de fichiers CSV.
Since uploading thousands of CSV files seems a little far-fetched, I took that use case and began to wonder how fast I could get the API to run. In this blog post, I will explain what I tried and how I eventually came to a program that could get around 100 000 validations en 55 secondes (Whereas in the UI I got around 100,000 validations in 1 minute 10 seconds). And while this still would take about 100 hours to get done with about 654 million validations, this script can run in the background saving significant time.
La version finale de ce programme est disponible here.
Ma première erreur : utiliser Python
Python est l'un de mes langages de programmation préférés. Il excelle dans de nombreux domaines et est incroyablement simple. Cependant, il y a un domaine dans lequel il n'excelle pas, c'est celui des processus concurrents. Bien que Python ait la capacité d'exécuter des fonctions asynchrones, il dispose de ce que l'on appelle le verrouillage de l'interpréteur global de Python ou GIL.
"Le Global Interpreter Lock (GIL) de Python, en termes simples, est un mutex (ou un verrou) qui permet à un seul thread de prendre le contrôle de l'interpréteur Python.
Cela signifie qu'un seul thread peut se trouver dans un état d'exécution à un moment donné. L'impact de la GIL n'est pas visible pour les développeurs qui exécutent des programmes à un seul thread, mais il peut constituer un goulot d'étranglement pour les codes multithreads et liés à l'unité centrale.
Since the GIL allows only one thread to execute at a time even in a multi-threaded architecture with more than one CPU core, the GIL has gained a reputation as an “infamous” feature of Python.” (https://realpython.com/python-gil/)”
Au début, je ne connaissais pas la GIL et j'ai commencé à programmer en Python. À la fin, même si mon programme était asynchrone, il se bloquait, et quel que soit le nombre de threads que j'ajoutais, je n'obtenais toujours qu'environ 12 à 15 itérations par seconde.
La partie principale de la fonction asynchrone en Python est présentée ci-dessous :
async def validateRecipients(f, fh, apiKey, snooze, count): h = {'Authorization': apiKey, 'Accept': 'application/json'} with tqdm(total=count) as pbar: async with aiohttp.ClientSession() as session: for address in f: for i in address: thisReq = requests.compat.urljoin(url, i) async with session.get(thisReq,headers=h, ssl=False) as resp: content = await resp.json() row = content['results'] row['email'] = i fh.writerow(row) pbar.update(1)
J'ai donc abandonné l'utilisation de Python et je suis retourné à la planche à dessin...
J'ai choisi d'utiliser NodeJS en raison de sa capacité à effectuer des opérations d'entrée/sortie non bloquantes de manière extrêmement efficace. Je suis également assez familier avec la programmation en NodeJS.
Utilizing asynchronous aspects of NodeJS, this ended up working well. For more details about asynchronous programming in NodeJS, see https://blog.risingstack.com/node-hero-async-programming-in-node-js/
Ma deuxième erreur : essayer de lire le fichier en mémoire
Mon idée de départ était la suivante :
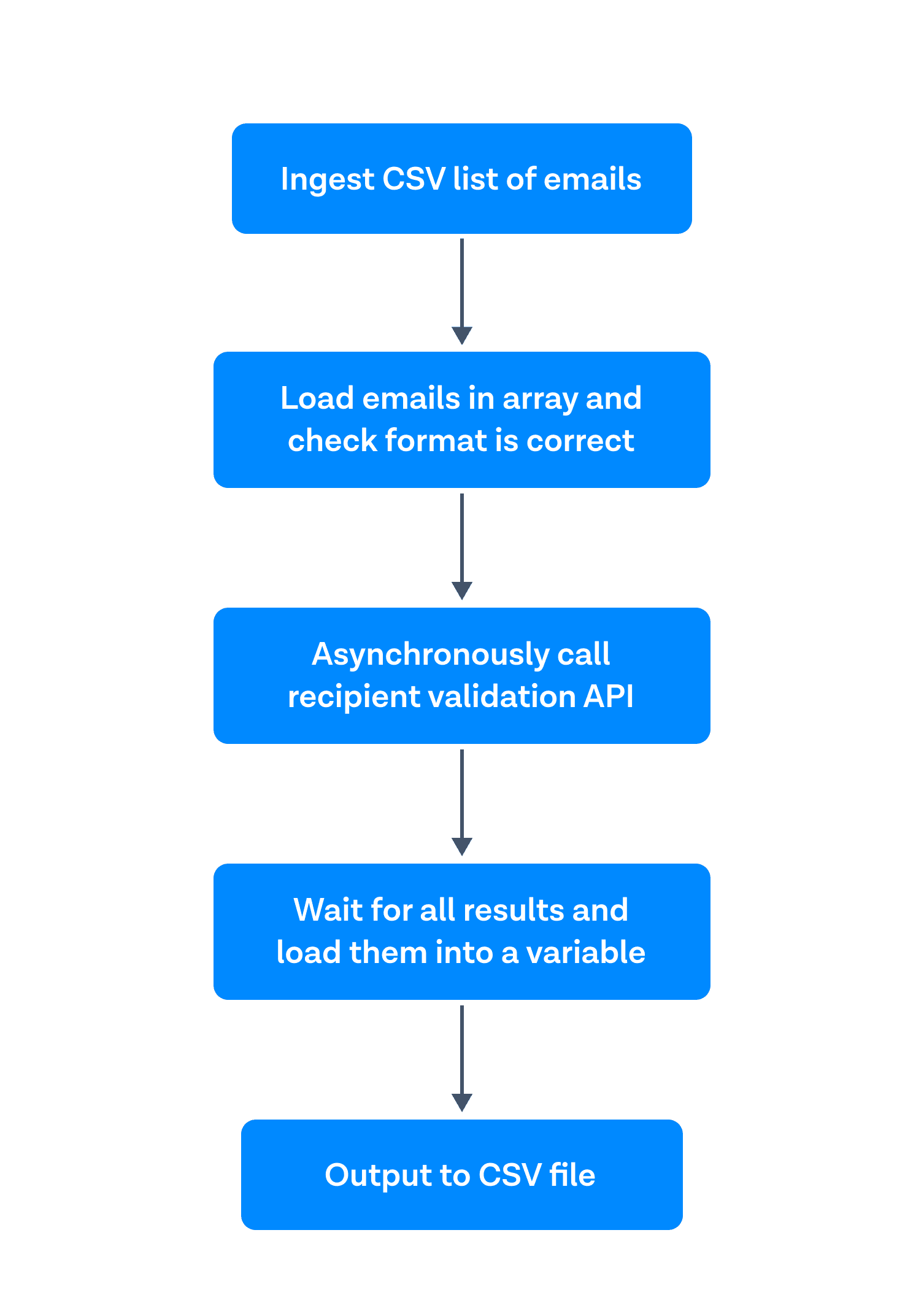
Tout d'abord, il s'agit d'ingérer une liste CSV d'e-mails. Deuxièmement, charger les courriels dans un tableau et vérifier qu'ils sont dans le bon format. Troisièmement, appeler de manière asynchrone l'API de validation des destinataires. Quatrièmement, attendre les résultats et les charger dans une variable. Et enfin, produire cette variable dans un fichier CSV.
This worked very well for smaller files. Le issue became when I tried to run 100,000 emails through. Le program stalled at around 12,000 validations. With the help of one of our front-end developers, I saw that the issue was with loading all the results into a variable (and therefore running out of memory quickly). If you would like to see the first iteration of this program, I have linked it here: Version 1 (NON RECOMMANDÉE).
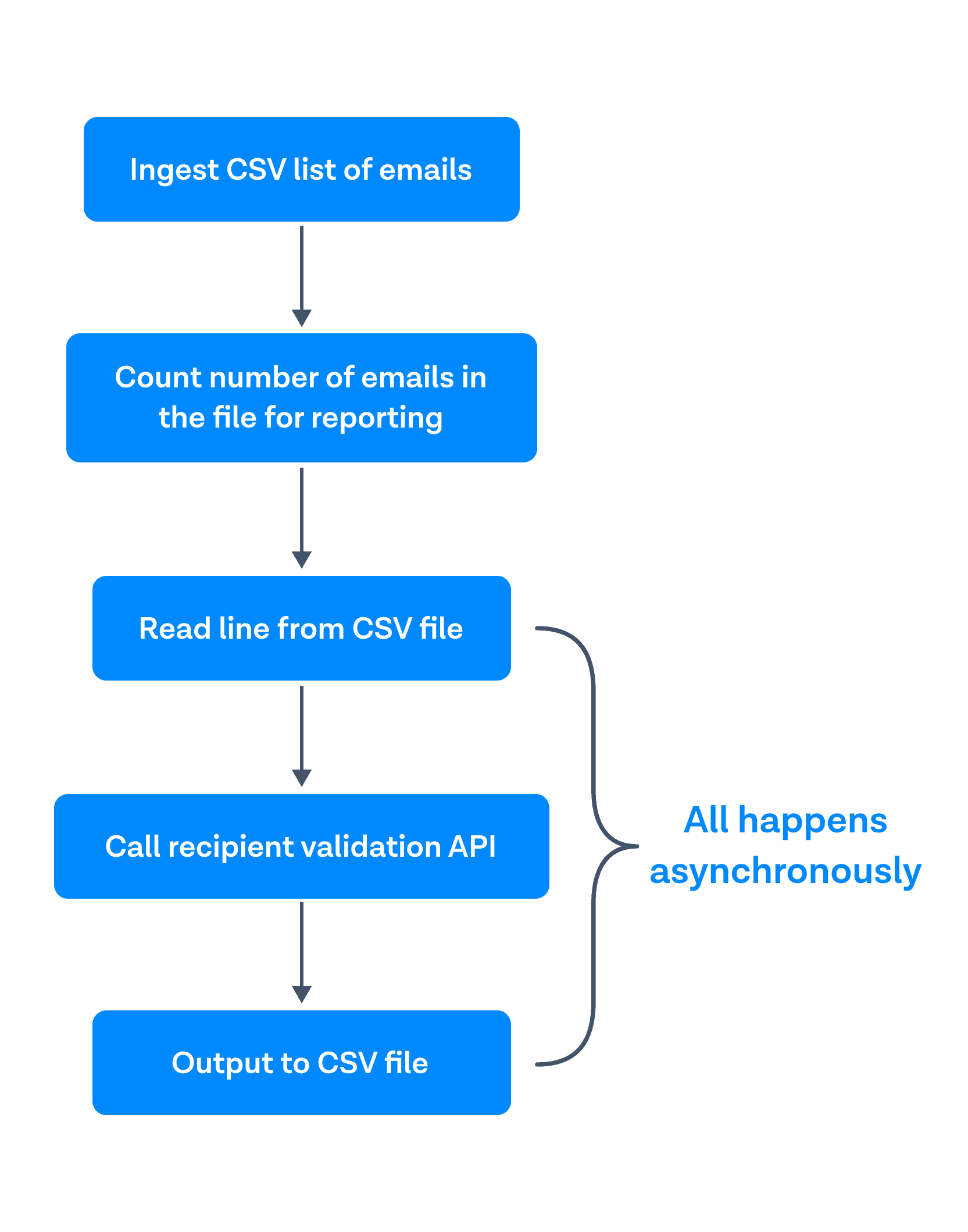
Tout d'abord, il s'agit d'ingérer une liste CSV de courriels. Deuxièmement, compter le nombre de courriels dans le fichier à des fins de reporting. Troisièmement, à mesure que chaque ligne est lue de manière asynchrone, appeler l'API de validation des destinataires et envoyer les résultats dans un fichier CSV.
Ainsi, pour chaque ligne lue, j'appelle l'API et j'écris les résultats de manière asynchrone afin de ne pas conserver ces données dans la mémoire à long terme. J'ai également supprimé la vérification de la syntaxe des courriels après avoir discuté avec l'équipe de validation des destinataires, qui m'a informé que la validation des destinataires comportait déjà des contrôles intégrés pour vérifier si un courriel était valide ou non.
Décomposition du code final
Après avoir lu et validé les arguments du terminal, j'exécute le code suivant. Tout d'abord, je lis le fichier CSV des courriels et je compte chaque ligne. Cette fonction a deux objectifs : 1) elle me permet de rendre compte avec précision de la progression du fichier [comme nous le verrons plus tard] et 2) elle me permet d'arrêter une minuterie lorsque le nombre d'e-mails dans le fichier est égal au nombre de validations effectuées. J'ai ajouté une minuterie afin de pouvoir effectuer des analyses comparatives et m'assurer que j'obtiens de bons résultats.
let count = 0; //Line count require("fs") .createReadStream(myArgs[1]) .on("data", function (chunk) { for (let i = 0; i < chunk.length; ++i) if (chunk[i] == 10) count++; }) //Reads the infile and increases the count for each line .on("close", function () { //At the end of the infile, after all lines have been counted, run the recipient validation function validateRecipients.validateRecipients(count, myArgs); });
J'appelle ensuite la fonction validateRecipients. Notez que cette fonction est asynchrone. Après avoir validé que les fichiers infile et outfile sont des CSV, j'écris une ligne d'en-tête et je démarre un programmateur en utilisant la bibliothèque JSDOM.
async function validateRecipients(email_count, myArgs) { if ( //If both the infile and outfile are in .csv format extname(myArgs[1]).toLowerCase() == ".csv" && extname(myArgs[3]).toLowerCase() == ".csv" ) { let completed = 0; //Counter for each API call email_count++; //Line counter returns #lines - 1, this is done to correct the number of lines //Start a timer const { window } = new JSDOM(); const start = window.performance.now(); const output = fs.createWriteStream(myArgs[3]); //Outfile output.write( "Email,Valid,Result,Reason,Is_Role,Is_Disposable,Is_Free,Delivery_Confidence\n" ); //Write the headers in the outfile
Le script suivant est vraiment le gros du programme, je vais donc le décomposer et expliquer ce qui se passe. Pour chaque ligne du fichier inf :
Asynchronously take that line and call the API de validation des destinataires.
fs.createReadStream(myArgs[1]) .pipe(csv.parse({ headers: false })) .on("data", async (email) => { let url = SPARKPOST_HOST + "/api/v1/recipient-validation/single/" + email; await axios .get(url, { headers: { Authorization: SPARKPOST_API_KEY, }, }) //For each row read in from the infile, call the SparkPost Recipient Validation API
Ensuite, dans la réponse
Ajouter l'email au JSON (pour pouvoir imprimer l'email dans le CSV)
Valider si la raison est nulle, et si c'est le cas, remplir une valeur vide (ceci afin que le format CSV soit cohérent, car dans certains cas la raison est donnée dans la réponse).
Définir les options et les clés du module json2csv.
Convertir le JSON en CSV et le sortir (en utilisant json2csv)
Ecrire l'état d'avancement dans le terminal
Enfin, si le nombre de courriels dans le fichier = les validations effectuées, arrêter le minuteur et imprimer les résultats.
.then(function (response) { response.data.results.email = String(email); //Adds the email as a value/key pair à la response JSON to be used for output response.data.results.reason ? null : (response.data.results.reason = ""); //If reason is null, set it to blank so the CSV is uniform //Utilizes json-2-csv to convert the JSON to CSV format and output let options = { prependHeader: false, //Disables JSON values from being added as header rows for every line keys: [ "results.email", "results.valid", "results.result", "results.reason", "results.is_role", "results.is_disposable", "results.is_free", "results.delivery_confidence", ], //Sets the order of keys }; let json2csvCallback = function (err, csv) { if (err) throw err; output.write(`${csv}\n`); }; converter.json2csv(response.data, json2csvCallback, options); completed++; //Increase the API counter process.stdout.write(`Done with ${completed} / ${email_count}\r`); //Output status of Completed / Total to the console without showing new lines //If all emails have completed validation if (completed == email_count) { const stop = window.performance.now(); //Stop the timer console.log( `All emails successfully validated in ${ (stop - start) / 1000 } seconds` ); } })
Un dernier problème que j'ai rencontré, c'est qu'alors que cela fonctionnait très bien sur Mac, j'ai rencontré l'erreur suivante sous Windows après environ 10 000 validations :
Erreur : connect ENOBUFS XX.XX.XXX.XXX:443 - Local (undefined:undefined) with email XXXXXXX@XXXXXXXXXX.XXX
After doing some further research, it appears to be an issue with the NodeJS HTTP client connection pool not reusing connections. I found this Article de Stackoverflow on the issue, and after further digging, found a good configuration par défaut for the axios library that resolved this issue. I am still not certain why this issue only happens on Windows and not on Mac.
Prochaines étapes
Ce programme est destiné à ceux qui recherchent un programme simple et rapide qui prend un csv, appelle l'API de validation des destinataires et produit un csv.
Ce programme pourrait être complété par les éléments suivants :
Construire un front-end ou une interface utilisateur plus facile à utiliser
Meilleure gestion des erreurs et des tentatives d'appel, car si, pour une raison quelconque, l'API émet une erreur, le programme ne tente pas de nouveau l'appel.
Je serais également curieux de voir si des résultats plus rapides peuvent être obtenus avec un autre langage tel que Golang ou Erlang/Elixir.
Please feel free to provide me any commentaires ou suggestions for expanding this project.