
May 26, 2022
Building a Bulk Asynchronous Bird Recipient Validation Tool
One of the questions we occasionally receive is, how can I bulk validate email lists with recipient validation? There are two options here, one is to upload a file through the SparkPost UI for validation, and the other is to make individual calls per email to the API (as the API is single email validation).
The first option works great but has a limitation of 20Mb (about 500,000 addresses). What if someone has an email list containing millions of addresses? It could mean splitting that up into 1,000’s of CSV file uploads.
Since uploading thousands of CSV files seems a little far-fetched, I took that use case and began to wonder how fast I could get the API to run. In this blog post, I will explain what I tried and how I eventually came to a program that could get around 100,000 validations in 55 seconds (Whereas in the UI I got around 100,000 validations in 1 minute 10 seconds). And while this still would take about 100 hours to get done with about 654 million validations, this script can run in the background saving significant time.
The final version of this program can be found here.
My first mistake: using Python
Python is one of my favorite programming languages. It excels in many areas and is incredibly straightforward. However, one area it does not excel in is concurrent processes. While python does have the ability to run asynchronous functions, it has what is known as The Python Global Interpreter Lock or GIL.
“The Python Global Interpreter Lock or GIL, in simple words, is a mutex (or a lock) that allows only one thread to hold the control of the Python interpreter.
This means that only one thread can be in a state of execution at any point in time. The impact of the GIL isn’t visible to developers who execute single-threaded programs, but it can be a performance bottleneck in CPU-bound and multi-threaded code.
Since the GIL allows only one thread to execute at a time even in a multi-threaded architecture with more than one CPU core, the GIL has gained a reputation as an “infamous” feature of Python.” (https://realpython.com/python-gil/)”
At first, I wasn’t aware of the GIL, so I started programming in python. At the finish, even though my program was asynchronous, it was getting locked up, and no matter how many threads I added, I still only got about 12-15 iterations per second.
The main portion of the asynchronous function in Python can be seen below:
async def validateRecipients(f, fh, apiKey, snooze, count): h = {'Authorization': apiKey, 'Accept': 'application/json'} with tqdm(total=count) as pbar: async with aiohttp.ClientSession() as session: for address in f: for i in address: thisReq = requests.compat.urljoin(url, i) async with session.get(thisReq,headers=h, ssl=False) as resp: content = await resp.json() row = content['results'] row['email'] = i fh.writerow(row) pbar.update(1)
So I scrapped using Python and went back to the drawing board…
I settled on utilizing NodeJS due to its ability to perform non-blocking i/o operations extremely well. I also am pretty familiar with programming in NodeJS.
Utilizing asynchronous aspects of NodeJS, this ended up working well. For more details about asynchronous programming in NodeJS, see https://blog.risingstack.com/node-hero-async-programming-in-node-js/
My second mistake: trying to read the file into memory
My initial idea was as follows:
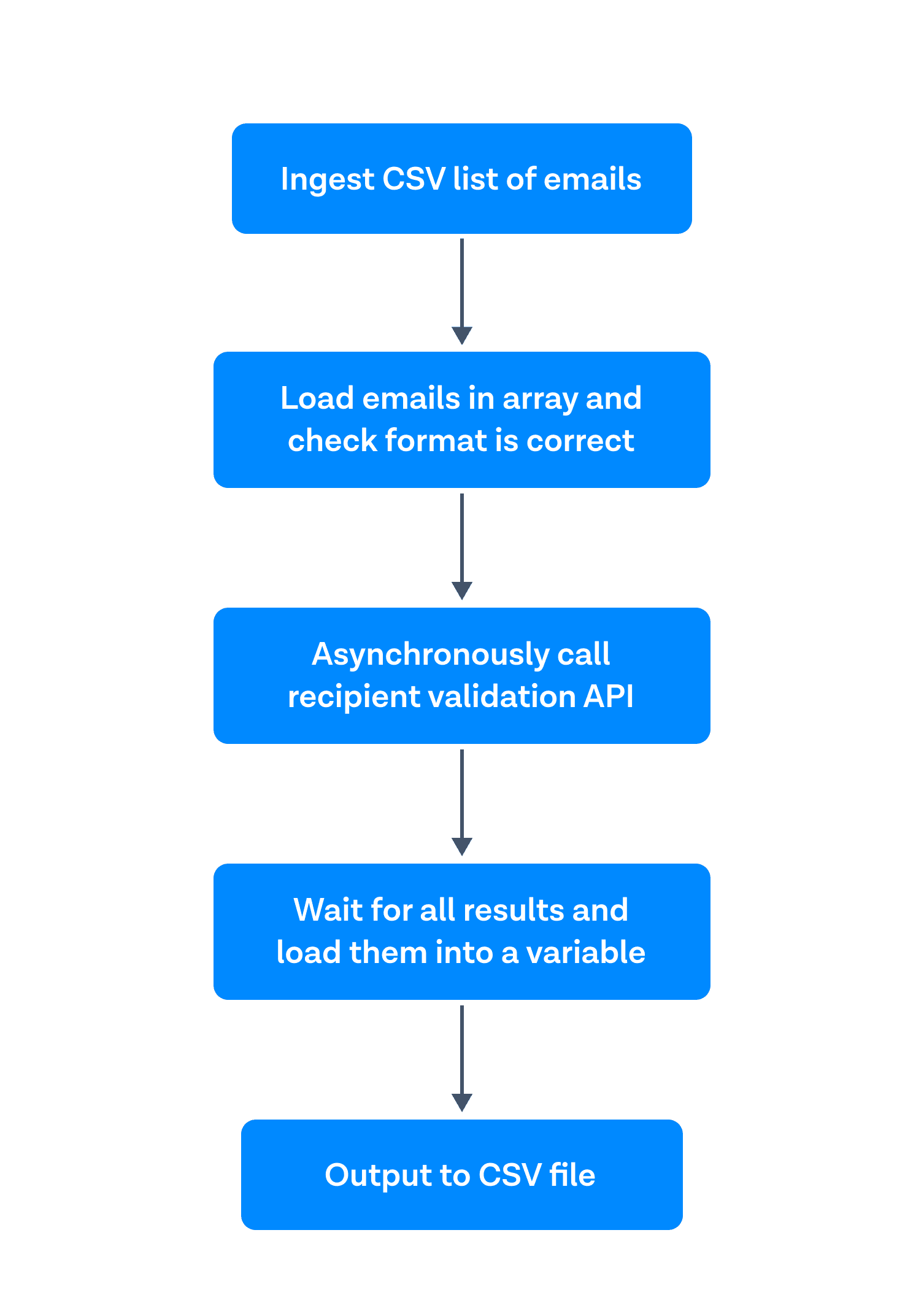
First, ingest a CSV list of emails. Second, load the emails into an array and check that they are in the correct format. Third, asynchronously call the recipient validation API. Fourth, wait for the results and load them into a variable. And finally, output this variable to a CSV file.
This worked very well for smaller files. The issue became when I tried to run 100,000 emails through. The program stalled at around 12,000 validations. With the help of one of our front-end developers, I saw that the issue was with loading all the results into a variable (and therefore running out of memory quickly). If you would like to see the first iteration of this program, I have linked it here: Version 1 (NOT RECOMMENDED).
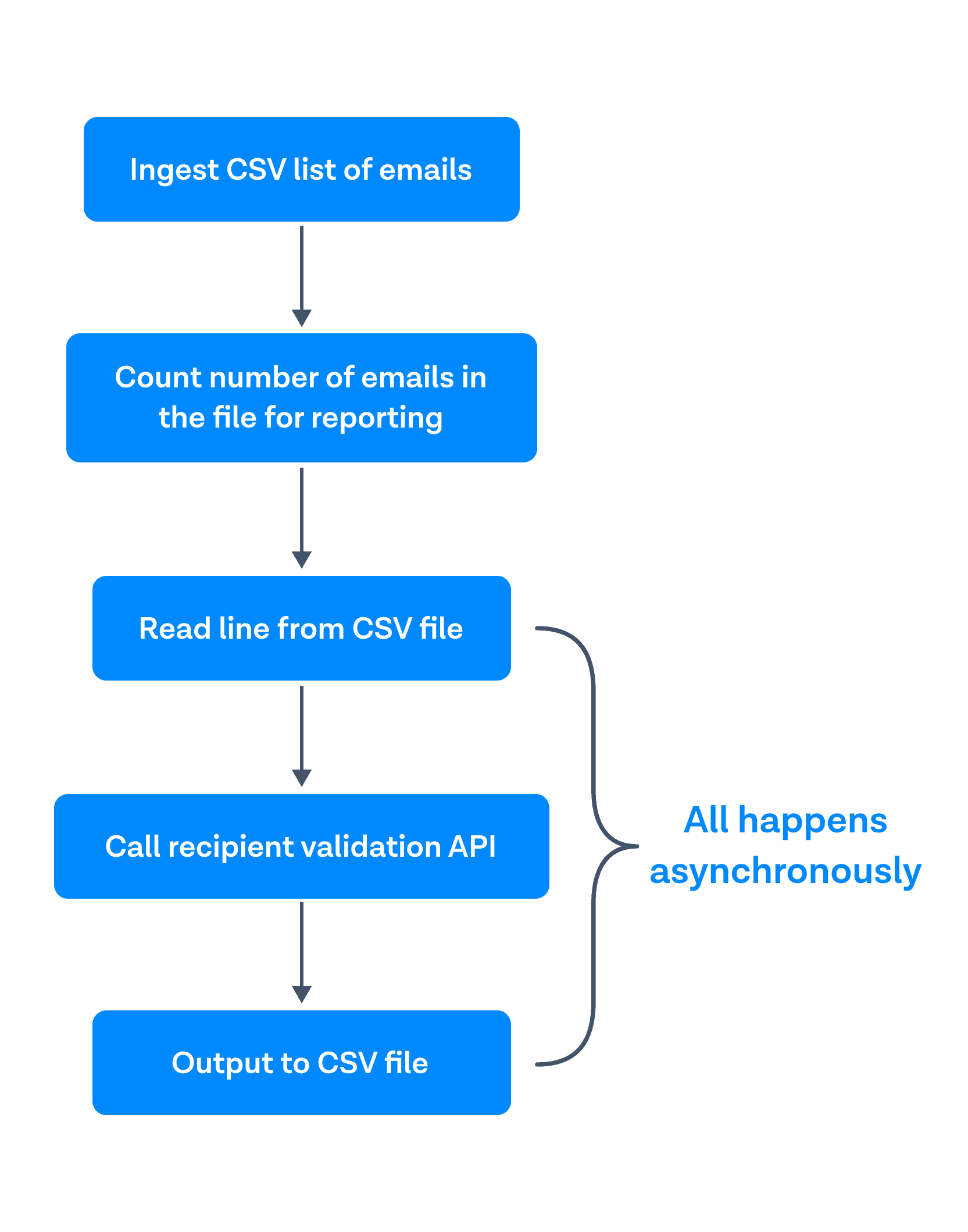
First, ingest a CSV list of emails. Second, count the number of emails in the file for reporting purposes. Third, as each line is read asynchronously, call the recipient validation API and output the results to a CSV file.
Thus, for each line read in, I call the API and write out the results asynchronously so as to not keep any of this data in long-term memory. I also removed the email syntax checking after speaking with the recipient validation team, as they informed me recipient validation already has checks built in to check if an email is valid or not.
Breaking down the final code
After reading in and validating the terminal arguments, I run the following code. First, I read in the CSV file of emails and count each line. There are two purposes of this function, 1) it allows me to accurately report on file progress [as we will see later], and 2) it allows me to stop a timer when the number of emails in the file equals completed validations. I added a timer so I can run benchmarks and ensure I am getting good results.
let count = 0; //Line count require("fs") .createReadStream(myArgs[1]) .on("data", function (chunk) { for (let i = 0; i < chunk.length; ++i) if (chunk[i] == 10) count++; }) //Reads the infile and increases the count for each line .on("close", function () { //At the end of the infile, after all lines have been counted, run the recipient validation function validateRecipients.validateRecipients(count, myArgs); });
I then call the validateRecipients function. Note this function is asynchronous. After validating that the infile and outfile are CSV, I write a header row, and start a program timer using the JSDOM library.
async function validateRecipients(email_count, myArgs) { if ( //If both the infile and outfile are in .csv format extname(myArgs[1]).toLowerCase() == ".csv" && extname(myArgs[3]).toLowerCase() == ".csv" ) { let completed = 0; //Counter for each API call email_count++; //Line counter returns #lines - 1, this is done to correct the number of lines //Start a timer const { window } = new JSDOM(); const start = window.performance.now(); const output = fs.createWriteStream(myArgs[3]); //Outfile output.write( "Email,Valid,Result,Reason,Is_Role,Is_Disposable,Is_Free,Delivery_Confidence\n" ); //Write the headers in the outfile
The following script is really the bulk of the program so I will break it up and explain what is happening. For each line of the infile:
Asynchronously take that line and call the recipient validation API.
fs.createReadStream(myArgs[1]) .pipe(csv.parse({ headers: false })) .on("data", async (email) => { let url = SPARKPOST_HOST + "/api/v1/recipient-validation/single/" + email; await axios .get(url, { headers: { Authorization: SPARKPOST_API_KEY, }, }) //For each row read in from the infile, call the SparkPost Recipient Validation API
Then, on the response
Add the email to the JSON (to be able to print out the email in the CSV)
Validate if reason is null, and if so, populate an empty value (this is so the CSV format is consistent, as in some cases reason is given in the response)
Set the options and keys for the json2csv module.
Convert the JSON to CSV and output (utilizing json2csv)
Write progress in the terminal
Finally, if number of emails in the file = completed validations, stop the timer and print out the results
.then(function (response) { response.data.results.email = String(email); //Adds the email as a value/key pair to the response JSON to be used for output response.data.results.reason ? null : (response.data.results.reason = ""); //If reason is null, set it to blank so the CSV is uniform //Utilizes json-2-csv to convert the JSON to CSV format and output let options = { prependHeader: false, //Disables JSON values from being added as header rows for every line keys: [ "results.email", "results.valid", "results.result", "results.reason", "results.is_role", "results.is_disposable", "results.is_free", "results.delivery_confidence", ], //Sets the order of keys }; let json2csvCallback = function (err, csv) { if (err) throw err; output.write(`${csv}\n`); }; converter.json2csv(response.data, json2csvCallback, options); completed++; //Increase the API counter process.stdout.write(`Done with ${completed} / ${email_count}\r`); //Output status of Completed / Total to the console without showing new lines //If all emails have completed validation if (completed == email_count) { const stop = window.performance.now(); //Stop the timer console.log( `All emails successfully validated in ${ (stop - start) / 1000 } seconds` ); } })
One final issue I found was while this worked great on Mac, I ran into the following error using Windows after around 10,000 validations:
Error: connect ENOBUFS XX.XX.XXX.XXX:443 – Local (undefined:undefined) with email XXXXXXX@XXXXXXXXXX.XXX
After doing some further research, it appears to be an issue with the NodeJS HTTP client connection pool not reusing connections. I found this Stackoverflow article on the issue, and after further digging, found a good default config for the axios library that resolved this issue. I am still not certain why this issue only happens on Windows and not on Mac.
Next Steps
For someone who is looking for a simple fast program that takes in a csv, calls the recipient validation API, and outputs a CSV, this program is for you.
Some additions to this program would be the following:
Build a front end or easier UI for use
Better error and retry handling because if for some reason the API throws an error, the program currently doesn’t retry the call
I’d also be curious to see if faster results could be achieved with another language such as Golang or Erlang/Elixir.
Please feel free to provide me any feedback or suggestions for expanding this project.